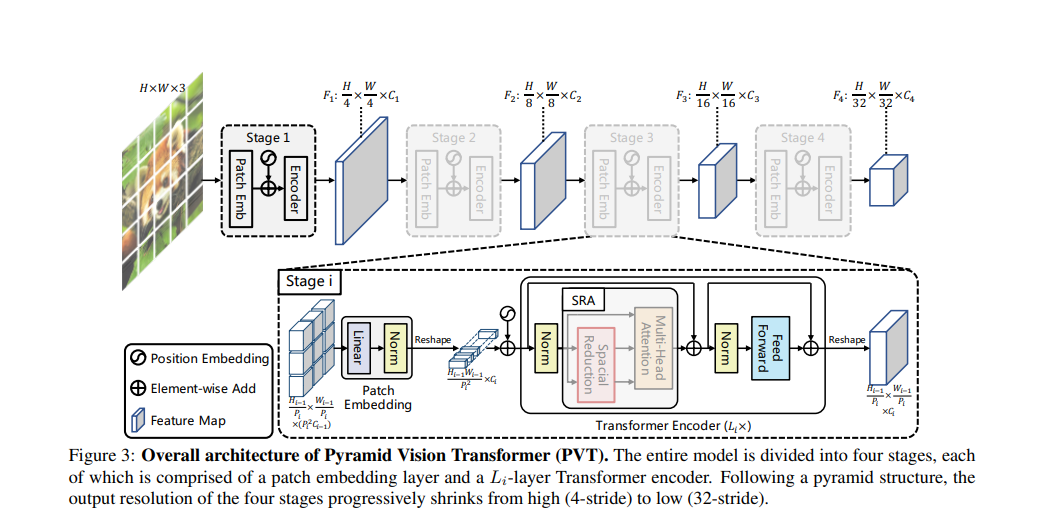
# Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
- 最初の各ピクセル・レベル密な予測タスクのための純粋な Transformer バックボーンの PVT を提案した.
- 漸進的縮小ピラミッドと空間縮小 attention (SRA) を設計し Transformer の資源消費を削減した.
- 画像分類,目標検出と領域分割の様々なタスクで PVT の有効性を検証した.
# アブスト
畳み込みニューラル ネットワーク (CNN) はコンピューター・ビジョンで大成功を収めていますが,この研究では多くの密な予測タスク(Dense prediction task)に使用できる,よりシンプルで畳み込みのないバックボーン・ネットワークを提案する.特に画像分類用に設計された最近提案されたビジョン トランスフォーマー (ViT) とは異なり,ピラミッド・ビジョン・トランスフォーマー (PVT) を導入する.これにより,Transformer をさまざまな高密度予測タスクに移植する際の困難が克服される.PVT には,現在の最先端技術と比較していくつかのメリットがる.(1) 通常,低解像度の出力を生成し,計算コストとメモリ・コストが高くなる ViT とは異なり,PVT は画像の高密度パーティションでトレーニングし高密度予測に重要な高出力解像度を実現できるだけでなく,漸進的縮小ピラミッドを使用して、大きな特徴マップの計算を削減する.(2) PVT は CNN と Transformer の両方の利点を継承し畳み込みのない様々なビジョン・タスクの統合バックボーンになり,CNN バックボーンの直接の代替として使用できる.(3) 大規模な実験を通じて PVT を検証し、オブジェクト検出,インスタンス,セマンティック・セグメンテーションなど,多くのダウンストリーム・タスクのパフォーマンスを向上させることを示している.例えば,同等の数のパラメーターを使用すると,PVT+RetinaNet は COCO データセットで 40.4 AP を達成し,ResNet50+RetinNet (36.3 AP) を 4.1 絶対 AP で上回る (図 2 を参照).PVT が,ピクセル・レベルの予測のための代替の有用なバックボーンとして機能し,将来の研究を促進することを期待している.
# イントロ
(つづき)
# 専門用語和英対照
| 日本語 | 英語 |
|---|---|